CUDA.jl 3.0
Tim Besard
CUDA.jl 3.0 is a significant, semi-breaking release that features greatly improved multi-tasking and multi-threading, support for CUDA 11.2 and its new memory allocator, compiler tooling for GPU method overrides, device-side random number generation and a completely revamped cuDNN interface.
Improved multi-tasking and multi-threading
Before this release, CUDA operations were enqueued on a single global stream, and many of these operations (like copying memory, or synchronizing execution) were fully blocking. This posed difficulties when using multiple tasks to perform independent operations: Blocking operations prevent all tasks from making progress, and using the same stream introduces unintended dependencies on otherwise independend operations. CUDA.jl now uses private streams for each Julia task, and avoids blocking operations where possible, enabling task-based concurrent execution. It is also possible to use different devices on each task, and there is experimental support for executing those tasks from different threads.
A picture snippet of code is worth a thousand words, so let's demonstrate using a computation that uses both a library function (GEMM from CUBLAS) and a native Julia broadcast kernel:
using CUDA, LinearAlgebra
function compute(a,b,c)
mul!(c, a, b)
broadcast!(sin, c, c)
synchronize()
c
endTo execute multiple invocations of this function concurrently, we can simply use Julia's task-based programming interfaces and wrap each call to compute in an @async block. Then, we synchronize execution again by wrapping in a @sync block:
function iteration(a,b,c)
results = Vector{Any}(undef, 2)
NVTX.@range "computation" @sync begin
@async begin
results[1] = compute(a,b,c)
end
@async begin
results[2] = compute(a,b,c)
end
end
NVTX.@range "comparison" Array(results[1]) == Array(results[2])
endThe calls to the @range macro from NVTX, a submodule of CUDA.jl, will visualize the different phases of execution when we profile our program. We now invoke our function using some random data:
function main(N=1024)
a = CUDA.rand(N,N)
b = CUDA.rand(N,N)
c = CUDA.rand(N,N)
# make sure this data can be used by other tasks!
synchronize()
# warm-up
iteration(a,b,c)
GC.gc(true)
NVTX.@range "main" iteration(a,b,c)
endThe snippet above illustrates one breaking aspect of this release: Because each task uses its own stream, you now need to synchronize when re-using data in another task. Although it is unlikely that any user code was relying on the old behavior, it is technically a breaking change, and as such we are bumping the major version of the CUDA.jl package.
If we profile these our program using NSight Systems, we can see how the execution of both calls to compute was overlapped:
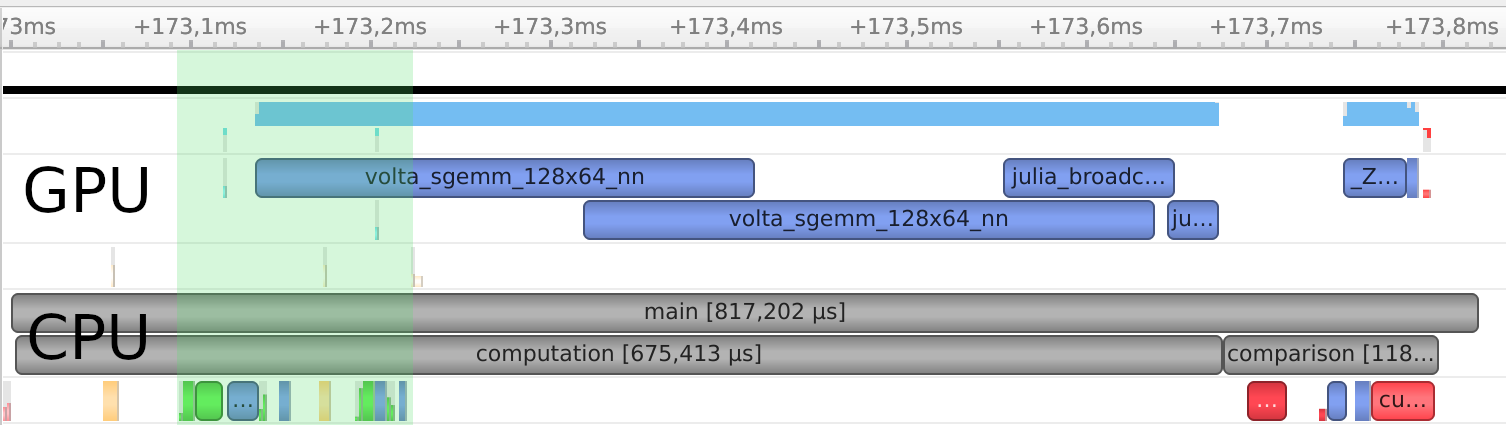
The region highlighted in green was spent enqueueing operations from the CPU, which includes the call to synchronize(). This used to be a blocking operation, whereas now it only synchronizes the task-local stream while yielding to the Julia scheduler so that it can continue execution on another task. For synchronizing the entire device, use the new device_synchronize() function.
The remainder of computation was then spent executing kernels. Here, execution was overlapped, but that obviously depends on the exact characteristics of the computations and your GPU. Also note that copying to and from the CPU is always going to block for some time, unless the memory was page-locked. CUDA.jl now supports locking memory like that using the pin function; for more details refer to the CUDA.jl documentation on tasks and threads.
CUDA 11.2 and stream-ordered allocations
CUDA.jl now also fully supports CUDA 11.2, and it will default to using that version of the toolkit if your driver supports it. The release came with several new features, such as the new stream-ordered memory allocator. Without going into details, it is now possible to asynchonously allocate memory, obviating much of the need to cache those allocations in a memory pool. Initial benchmarks have shown nice speed-ups from using this allocator, while lowering memory pressure and thus reducing invocations of the Julia garbage collector.
When using CUDA 11.2, CUDA.jl will default to the CUDA-backed memory pool and disable its own caching layer. If you want to compare performance, you can still use the old allocator and caching memory pool by setting the JULIA_CUDA_MEMORY_POOL environment variable to, e.g. binned. On older versions of CUDA, the binned pool is still used by default.
GPU method overrides
With the new AbstractInterpreter functionality in Julia 1.6, it is now much easier to further customize the Base compiler. This has enabled us to develop a mechanism for overriding methods with GPU-specific counterparts. It used to be required to explicitly pick CUDA-specific versions, e.g. CUDA.sin, because the Base version performed some GPU-incompatible operation. This was problematic as it did not compose with generic code, and the CUDA-specific versions often lacked support for specific combinations of argument types (for example, CUDA.sin(::Complex) was not supported).
With CUDA 3.0, it is possible to define GPU-specific methods that override an existing definition, without requiring a new function type. For now, this functionality is private to CUDA.jl, but we expect to make it available to other packages starting with Julia 1.7.
This functionality has unblocked many issues, as can be seen in the corresponding pull request. It is now no longer needed to prefix a call with the CUDA module to ensure a GPU-compatible version is used. Furthermore, it also protects users from accidentally calling GPU intrinsics, as doing so will now result in an error instead of a crash:
julia> CUDA.saturate(1f0)
ERROR: This function is not intended for use on the CPU
Stacktrace:
[1] error(s::String)
@ Base ./error.jl:33
[2] saturate(x::Float32)
@ CUDA ~/Julia/pkg/CUDA/src/device/intrinsics.jl:23
[3] top-level scope
@ REPL[10]:1Device-side random number generation
As an illustration of the value of GPU method overrides, CUDA.jl now provides a device-side random number generator that is accessible by simply calling rand() from a kernel:
julia> function kernel()
@cushow rand()
return
end
kernel (generic function with 1 method)
julia> @cuda kernel()
rand() = 0.668274This works by overriding the Random.default_rng() method, and providing a GPU-compatible random number generator: Building on exploratory work by @S-D-R, the current generator is a maximally equidistributed combined Tausworthe RNG that shares 32-bytes of random state across threads in a warp for performance. The generator performs well, but does not pass the Crush battery of tests, so PRs are welcome here to improve the implementation!
Note that for host-side operations, e.g. rand!(::CuArray), the generator is not yet used by default. Instead, we use CURAND whenever possible, and fall back to the slower but more full-featured GPUArrays.jl-generator in other cases.
Revamped cuDNN interface
Finally, the cuDNN wrappers have been completely revamped by @denizyuret. The goal of the redesign is to more faithfully map the cuDNN API to more natural Julia functions, so that packages like Knet.jl or NNlib.jl can more easily use advanced cuDNN features without having to resort to low-level C calls. For more details, refer to the design document. As part of this redesign, the high-level wrappers of CUDNN have been moved to a subpackage of NNlib.jl.