CUDA.jl 2.0
Tim Besard
Today we're releasing CUDA.jl 2.0, a breaking release with several new features. Highlights include initial support for Float16, a switch to CUDA's new stream model, a much-needed rework of the sparse array support and support for CUDA 11.1.
The release now requires Julia 1.5, and assumes a GPU with compute capability 5.0 or higher (although most of the package will still work with an older GPU).
Low- and mixed-precision operations
With NVIDIA's latest GPUs featuring more and more low-precision operations, CUDA.jl now starts to support these data types. For example, the CUBLAS wrappers can be used with (B)Float16 inputs (running under JULIA_DEBUG=CUBLAS to illustrate the called methods) thanks to the cublasGemmEx API call:
julia> mul!(CUDA.zeros(Float32,2,2),
cu(rand(Float16,2,2)),
cu(rand(Float16,2,2)))
I! cuBLAS (v11.0) function cublasStatus_t cublasGemmEx(...) called:
i! Atype: type=cudaDataType_t; val=CUDA_R_16F(2)
i! Btype: type=cudaDataType_t; val=CUDA_R_16F(2)
i! Ctype: type=cudaDataType_t; val=CUDA_R_32F(0)
i! computeType: type=cublasComputeType_t; val=CUBLAS_COMPUTE_32F(68)
2×2 CuArray{Float32,2}:
0.481284 0.561241
1.12923 1.04541julia> using BFloat16s
julia> mul!(CUDA.zeros(BFloat16,2,2),
cu(BFloat16.(rand(2,2))),
cu(BFloat16.(rand(2,2))))
I! cuBLAS (v11.0) function cublasStatus_t cublasGemmEx(...) called:
i! Atype: type=cudaDataType_t; val=CUDA_R_16BF(14)
i! Btype: type=cudaDataType_t; val=CUDA_R_16BF(14)
i! Ctype: type=cudaDataType_t; val=CUDA_R_16BF(14)
i! computeType: type=cublasComputeType_t; val=CUBLAS_COMPUTE_32F(68)
2×2 CuArray{BFloat16,2}:
0.300781 0.71875
0.0163574 0.0241699Alternatively, CUBLAS can be configured to automatically down-cast 32-bit inputs to Float16. This is now exposed through a task-local CUDA.jl math mode:
julia> CUDA.math_mode!(CUDA.FAST_MATH; precision=:Float16)
julia> mul!(CuArray(zeros(Float32,2,2)),
CuArray(rand(Float32,2,2)),
CuArray(rand(Float32,2,2)))
I! cuBLAS (v11.0) function cublasStatus_t cublasGemmEx(...) called:
i! Atype: type=cudaDataType_t; val=CUDA_R_32F(0)
i! Btype: type=cudaDataType_t; val=CUDA_R_32F(0)
i! Ctype: type=cudaDataType_t; val=CUDA_R_32F(0)
i! computeType: type=cublasComputeType_t; val=CUBLAS_COMPUTE_32F_FAST_16F(74)
2×2 CuArray{Float32,2}:
0.175258 0.226159
0.511893 0.331351As part of these changes, CUDA.jl now defaults to using tensor cores. This may affect accuracy; use math mode PEDANTIC if you want the old behavior.
Work is under way to extend these capabilities to the rest of CUDA.jl, e.g., the CUDNN wrappers, or the native kernel programming capabilities.
New default stream semantics
In CUDA.jl 2.0 we're switching to CUDA's simplified stream programming model. This simplifies working with multiple streams, and opens up more possibilities for concurrent execution of GPU operations.
Multi-stream programming
In the old model, the default stream (used by all GPU operations unless specified otherwise) was a special stream whose commands could not be executed concurrently with commands on regular, explicitly-created streams. For example, if we interleave kernels executed on a dedicated stream with ones on the default one, execution was serialized:
using CUDA
N = 1 << 20
function kernel(x, n)
tid = threadIdx().x + (blockIdx().x-1) * blockDim().x
for i = tid:blockDim().x*gridDim().x:n
x[i] = CUDA.sqrt(CUDA.pow(3.14159f0, i))
end
return
end
num_streams = 8
for i in 1:num_streams
stream = CuStream()
data = CuArray{Float32}(undef, N)
@cuda blocks=1 threads=64 stream=stream kernel(data, N)
@cuda kernel(data, 0)
end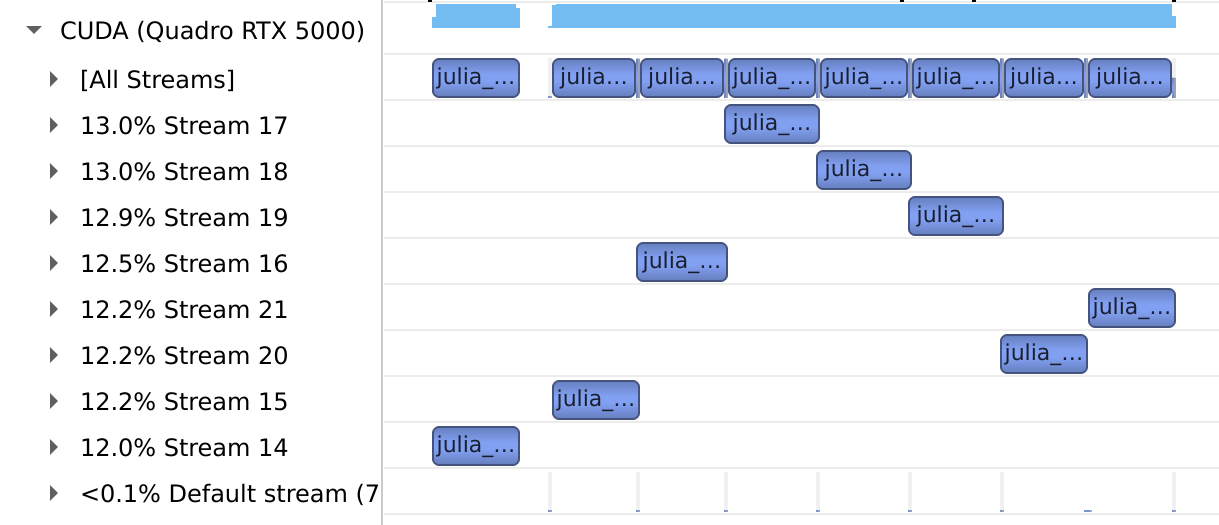
In the new model, default streams are regular streams and commands issued on them can execute concurrently with those on other streams:
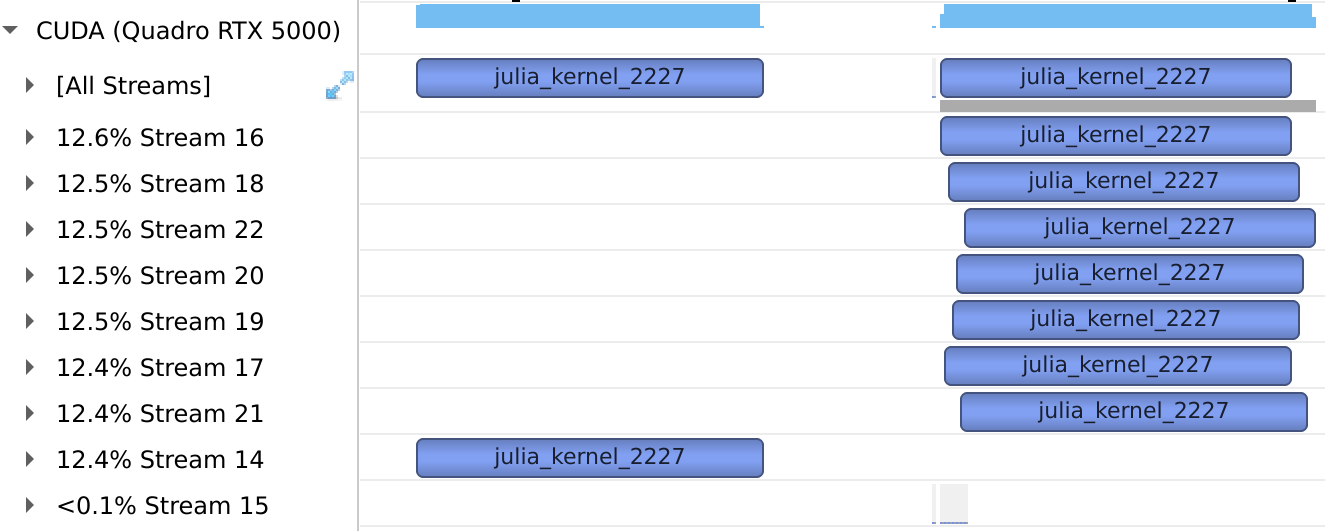
Multi-threading
Another consequence of the new stream model is that each thread gets its own default stream (accessible as CuStreamPerThread()). Together with Julia's threading capabilities, this makes it trivial to group independent work in tasks, benefiting from concurrent execution on the GPU where possible:
using CUDA
N = 1 << 20
function kernel(x, n)
tid = threadIdx().x + (blockIdx().x-1) * blockDim().x
for i = tid:blockDim().x*gridDim().x:n
x[i] = CUDA.sqrt(CUDA.pow(3.14159f0, i))
end
return
end
Threads.@threads for i in 1:Threads.nthreads()
data = CuArray{Float32}(undef, N)
@cuda blocks=1 threads=64 kernel(data, N)
synchronize(CuDefaultStream())
end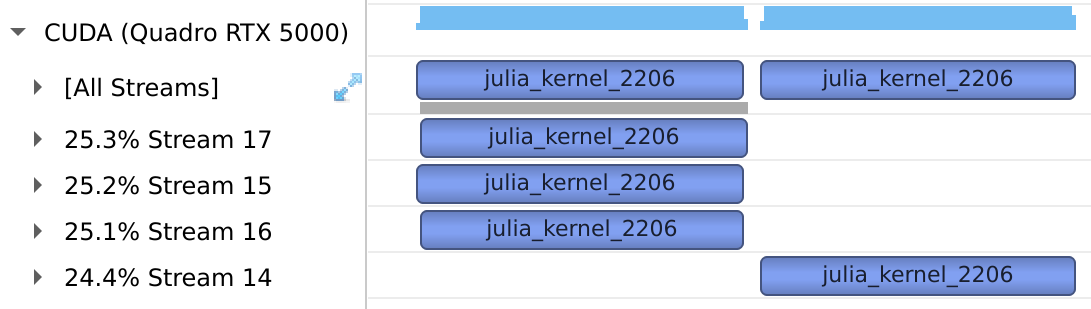
With the old model, execution would have been serialized because the default stream was the same across threads:

Future improvements will make this behavior configurable, such that users can use a different default stream per task.
Sparse array clean-up
As part of CUDA.jl 2.0, the sparse array support has been refactored, bringing them in line with other array types and their expected behavior. For example, the custom switch2 methods have been removed in favor of calls to convert and array constructors:
julia> using SparseArrays
julia> using CUDA, CUDA.CUSPARSE
julia> CuSparseMatrixCSC(CUDA.rand(2,2))
2×2 CuSparseMatrixCSC{Float32} with 4 stored entries:
[1, 1] = 0.124012
[2, 1] = 0.791714
[1, 2] = 0.487905
[2, 2] = 0.752466
julia> CuSparseMatrixCOO(sprand(2,2, 0.5))
2×2 CuSparseMatrixCOO{Float64} with 3 stored entries:
[1, 1] = 0.183183
[2, 1] = 0.966466
[2, 2] = 0.064101
julia> CuSparseMatrixCSR(ans)
2×2 CuSparseMatrixCSR{Float64} with 3 stored entries:
[1, 1] = 0.183183
[2, 1] = 0.966466
[2, 2] = 0.064101Initial support for the COO sparse matrix type has also been added, along with more better support for sparse matrix-vector multiplication.
Support for CUDA 11.1
This release also features support for the brand-new CUDA 11.1. As there is no compatible release of CUDNN or CUTENSOR yet, CUDA.jl won't automatically select this version, but you can force it to by setting the JULIA_CUDA_VERSION environment variable to 11.1:
julia> ENV["JULIA_CUDA_VERSION"] = "11.1"
julia> using CUDA
julia> CUDA.versioninfo()
CUDA toolkit 11.1.0, artifact installation
Libraries:
- CUDNN: missing
- CUTENSOR: missingMinor changes
Many other changes are part of this release:
Views, reshapes and array reinterpretations are now represented by the Base array wrappers, simplifying the CuArray type definition.
Support for
LinearAlgebra.reflect!androtate!Initial support for calling CUDA libraries with strided inputs