Paper: Flexible Performant GEMM Kernels on GPUs
Thomas Faingnaert, Tim Besard, Bjorn De Sutter
General Matrix Multiplication or GEMM kernels take center place in high performance computing and machine learning. Recent NVIDIA GPUs include GEMM accelerators, such as NVIDIA's Tensor Cores. In this paper we show how it is possible to program these accelerators from Julia, and present abstractions and interfaces that allow to do so efficiently without sacrificing performance.
A pre-print of the paper has been published on arXiv: arXiv:2009.12263.
The source code can be found on GitHub: thomasfaingnaert/GemmKernels.jl.
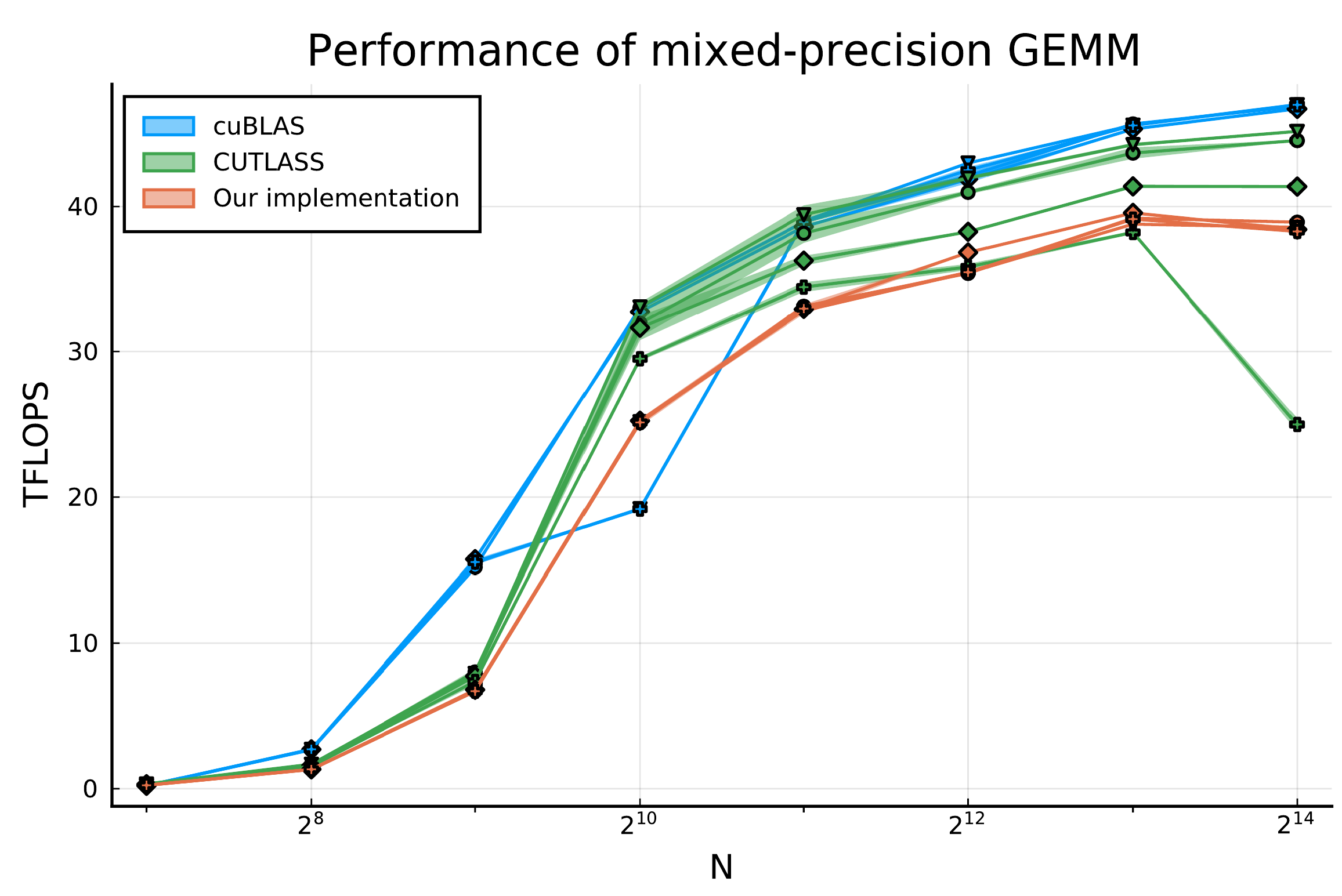
With the APIs from GemmKernels.jl, it is possible to instantiate GEMM kernels that perform in the same ball park as, and sometimes even outperform state-of-the-art libraries like CUBLAS and CUTLASS. For example, performing a mixed-precision multiplication of two 16-bit matrixes into a 32-bit accumulator (on different combinations of layouts):
The APIs are also highly flexible and allow customization of each step, e.g., to apply the activation function max(x, 0) for implementing a rectified linear unit (ReLU):
a = CuArray(rand(Float16, (M, K)))
b = CuArray(rand(Float16, (K, N)))
c = CuArray(rand(Float32, (M, N)))
d = similar(c)
conf = GemmKernels.get_config(
gemm_shape = (M = M, N = N, K = K),
operator = Operator.WMMAOp{16, 16, 16},
global_a_layout = Layout.AlignedColMajor{Float16},
global_c_layout = Layout.AlignedColMajor{Float32})
GemmKernels.matmul(
a, b, c, d, conf;
transform_regs_to_shared_d = Transform.Elementwise(x -> max(x, 0)))The GemmKernels.jl framework is written entirely in Julia, demonstrating the high-performance GPU programming capabilities of this language, but at the same time keeping the research accessible and easy to modify or repurpose by other Julia developers.